
Code: https://github.com/nrsyed/proboards-scraper
Documentation: https://nrsyed.github.io/proboards-scraper
- Part 1: Introduction and background
- Part 2: Implementation (project structure and scraper initialization)
- Part 3: Implementation (scraper internals)
Introduction
Disclaimer: It’s against ProBoards’s terms of service (TOS) to scrape content from a ProBoards forum. This project and blog post are purely for educational purposes and should not be used to scrape any ProBoards forum or website.
Though niche forums still exist, they’ve largely been supplanted by social media. This isn’t necessarily a bad thing—I love Instagram as much as the next guy—but there was something magical, something intangible about those personal forums of old, and their ability to foster a close-knit community of friends from around the world that “mega-forums” like Reddit and real-time platforms like Discord can’t quite capture. Some of that je ne sais quois might be the product of nostalgia from a time when both I and the internet were younger, when we AIMed instead of Zoomed, when the web felt like an untamed wild west and small forums were safe settlements—places to call “home” in the virtual world.
Philosophical waxings and wanings aside, back in the early 2000s, I was an administrator on one such forum hosted by ProBoards, one of the more popular forum hosting providers at the time. ProBoards is still around today and so is that forum, even if it hasn’t been active in years. I’m a sucker for nostalgia and felt it would be nice to archive the forum’s content, preserving it forever. The founder and owner of that forum, a close friend of mine, agreed.
Unfortunately, unlike most of its competitors, ProBoards doesn’t provide an option, paid or otherwise, for exporting a forum. And, as the disclaimer above states, scraping a forum violates the ProBoards TOS. Thus, this project is merely an exercise that demonstrates the use of several Python libraries and how they might be used for web scraping tasks. Furthermore, ProBoards may introduce changes to its platform that would break any tool designed to scrape its forums.
That said, let’s examine how we might hypothetically go about such a task. Part 1 (this post) lays the foundation for the scraper and its design. Parts 2 and 3 take a deep dive into the codebase to see how it works in practice.
Forum structure and SQL database schema
Before we can design a scraper, we must first 1) understand how a forum is organized and 2) decide how to represent this structure in a SQL database, which is where we’re going to store the information extracted by the scraper.
I won’t provide a link to an actual ProBoards forum in this post, but there is a directory of all ProBoards forums you can peruse for yourself.
Forum structure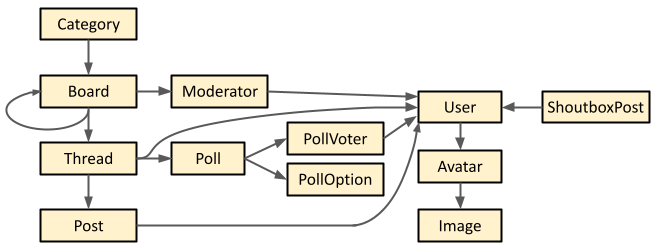
A ProBoards forum consists of named categories, visible on the forum homepage. A category is simply a group of boards. A board can have moderators, sub-boards (represented by the loop in the diagram above), and threads. A moderator is simply a user. A thread contains posts, may optionally have a poll, and is created by a user (the user that created a thread is usually the first poster in the thread, but this may not be true 100% of the time—for instance, if the first post was deleted by a moderator). Regarding polls: we can see the poll options (and how many votes each option has received) and which users have voted in the poll, but it’s not possible to see who voted for which option. Each post in a thread is associated with the user who made the post.
A forum also contains various images, including post smileys (aka emojis), the favicon, site background/style elements, and user avatars. In the diagram above, I’ve made avatars their own entity, which simply links a user to the image corresponding to their avatar. This isn’t strictly necessary; rather, it’s a design choice.
Some forums may also have a “shoutbox” enabled. This is simply a persistent chatbox that appears on the homepage. Shoutbox posts are, like normal posts, associated with the user that made them.
Breaking the site into these elements gives us a roadmap for building the scraper, as well as the schema for the SQL database. Each element in the figure above will be a table in the database.
Using asyncio for asynchronous scraping
Since a forum can comprise tens or hundreds of thousands of pages (user profiles, boards, a whole lot of threads with multiple pages, etc.), some form of concurrency or parallelism is necessary to scrape the site efficiently. We have a few options: 1) multithreading, 2) multiprocessing, and 3) asynchronous programming.
A Python process runs on a single core, and because of Python’s GIL (global interpreter lock), even multithreaded programs can only execute one thread at a time (unless the program uses a library that bypasses the GIL, like numpy). A Python program that uses the multiprocessing module can run on multiple cores, though each process has the same limitation. Because a process can only execute one thread at a time, multithreading is suited for I/O-bound (input/output–bound) tasks, like making HTTP requests or reading/writing files, since they are non-blocking (i.e., they involve waiting for something to finish happening, allowing the Python interpreter to do other things in the meantime). On the other hand, multiprocessing is preferable for CPU-bound tasks, which are blocking and actively require the CPU to be doing work (e.g., performing computations).
Then there’s option 3: asynchronous programming via the asyncio module,
which is single-threaded but “gives a feeling of concurrency,” as the
aforelinked article puts it, because it allows I/O-bound tasks to run in the
background while performing other tasks, which the Python interpreter can
switch to or step away from as necessary. This is similar to Python
multithreading except that, with asyncio, you tell the program when to step
away from a task using the await keyword. In a multithreaded program, on the
other hand, it’s up to the Python interpreter to determine how to schedule
different threads. Spawning threads also comes with overhead, which can make
multithreading less performant than asyncio.
I’m of the opinion that, in Python, one should use asyncio instead of multithreading whenever possible. Naturally, asyncio has its limitations and multithreading certainly has its place. However, we can get away with using asyncio instead of multithreading for a web scraper.
Not all I/O operations are awaitable by default in Python’s asyncio module. That includes making HTTP requests and reading/writing files. Luckily, the aiohttp and aiofiles libraries, respectively, fill these gaps. Although database read/write operations fall into the same category, SQLAlchemy doesn’t support asyncio at the moment. However, SQLAlchemy support for asyncio is in development and currently a beta feature. This is a relatively recent development that wasn’t available when I originally created this project, but it doesn’t really matter. The amount of time database I/O takes is negligible compared to the amount of time taken by HTTP requests—which comprise the bulk of the scraper’s work—and the aiohttp library already addresses that.
Design and architecture
The figure below illustrates the scraper’s architecture and data flow at a high level.
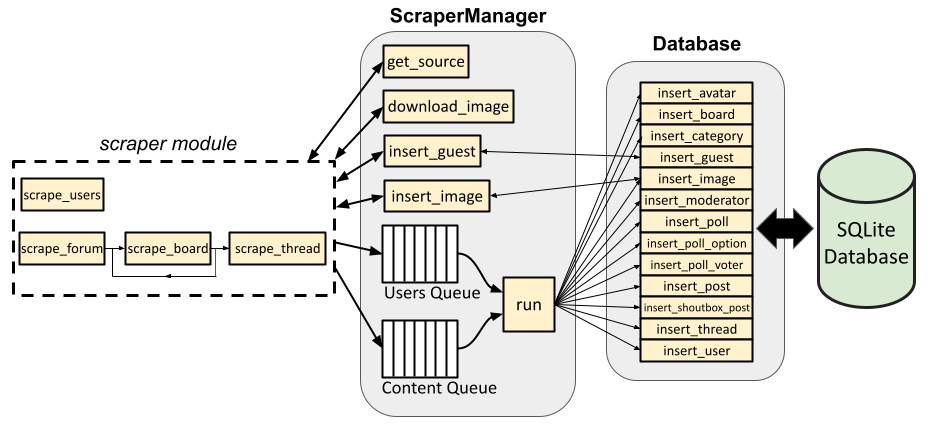
Scraper architecture
Let’s start at the right and work our way leftward.
SQLite database
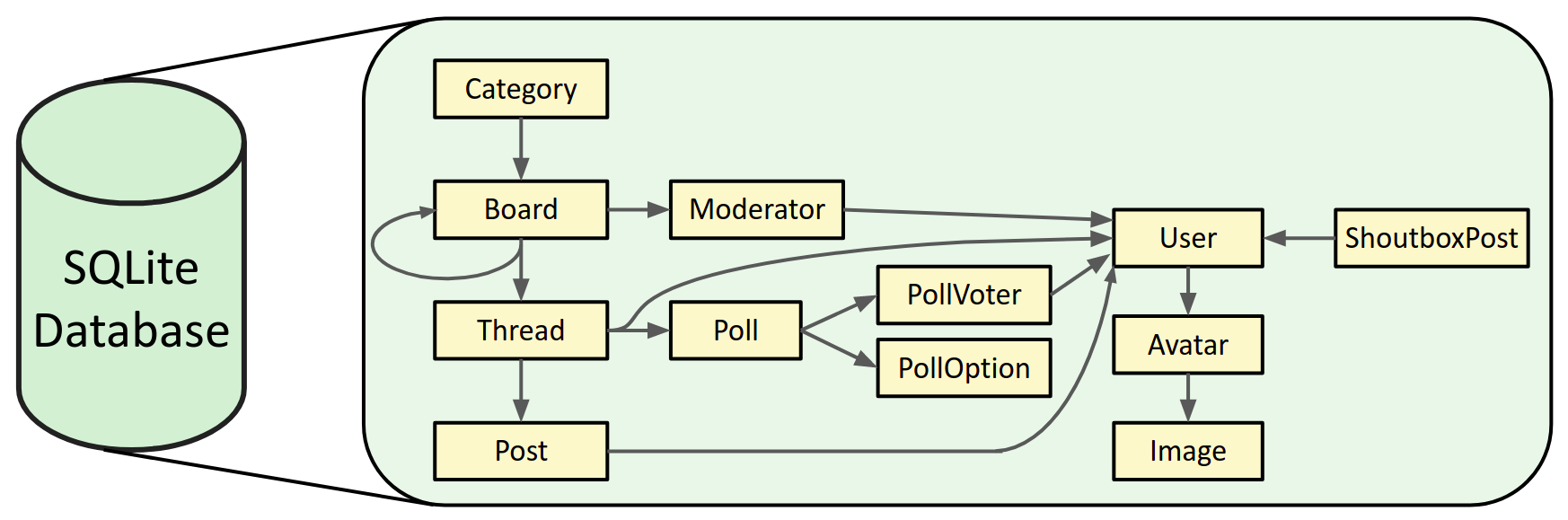
I used SQLite for the SQL database backend, as opposed to other dialects like MySQL or PostgreSQL, because it’s lightweight and more than sufficient for our needs. A SQLite database is just a single file on disk.
The SQL database schema consists of tables corresponding to the elements from the figure in the previous section. Each of these tables contains numerous attributes detailed in the documentation for the scraper’s database submodule. For example, the Users table includes the user id, age, birthdate, date registered, email, display name, signature, and other pieces of information that can be obtained from a user’s profile.
Database class

The Database class serves as an interface for the SQLite database. It provides convenient methods for querying the database and/or inserting objects into the tables described above. This way, the client (user or calling code) never has to worry about the mechanics of interacting directly with the database or writing SQL queries. In fact, I also didn’t have to worry about writing SQL queries because I used SQLAlchemy, an ORM that maps a SQL database’s schema to Python objects, thereby abstracting away the SQL and allowing me to write everything in pure Python. The Database class interacts with the SQL database via SQLAlchemy, and the client code interacts indirectly with the database via the Database class, whose methods return Python objects corresponding to items in the database.
ScraperManager class
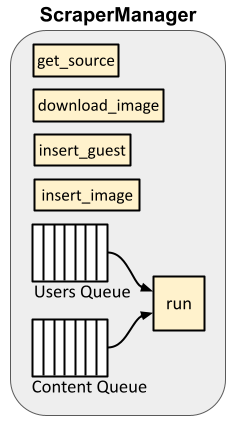
The ScraperManager class has a few purposes:
- Asynchronously handles all HTTP requests and adds delays between requests as needed to prevent request throttling by the server.
- Holds references to the Database class instance, as well as to the
aiohttpand Selenium Chromedriver session objects (which are used for making HTTP requests). - Acts as an intermediary between the core scraper functions (which actually parse HTML, deciding which links/pages to grab, etc.) and the database, determining which Database methods need to be called to insert items from the queues into the database.
#3 is mainly handled by the run() method, which continuously reads from two queues: a “users” queue and a “content” queue. Recall from the forum structure diagram above that many elements are associated with users. Therefore, it makes sense to add all the site’s members to the database, then add all other content. Because the site is scraped asynchronously, the scraper might be concurrently scraping/parsing both user profiles—which it adds to the users queue—and other content (boards, threads, posts, etc.), which it adds to the content queue. run() ensures that all users from the users queue are consumed and added to the database before it begins popping and processing items from the content queue.
scraper module
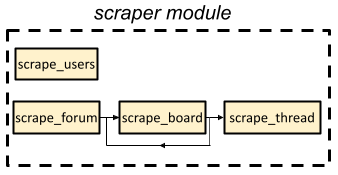
Lastly, there’s the scraper module, which is a sub-module in the proboards_scraper package that contains several async functions used to actually do the scraping (via a ScraperManager class instance to make HTTP requests and indirectly interact with the database, as described above). The scraper calls these functions as needed, some of which recursively call each other. For example, the scrape_forum() function grabs shoutbox posts, the site favicon, and categories from the main page, then calls scrape_board() on each board in each category. scrape_board(), in turns, calls itself recursively on any sub-boards, then iterates over all pages in the board and calls scrape_thread() on all the threads on each page.
Similarly, scrape_users() runs through each page of the member list and calls an async helper function named, predictably, scrape_user(), on each user profile.
Guests
Guests are users who aren’t actually registered on the site, i.e., they don’t show up in the site’s member list. Not all forums allow guests to make posts—the forum administrators can disable guest privileges if they so choose. Guests can also be deleted users. In any case, the scraper needs a way to handle them.
There are two issues: 1) guests have no user ID and 2) as mentioned in the ScraperManager class section above, we scrape all users first so that they already exist in the database when other content references them—however, guests don’t show up in the member list and cannot be scraped in advance.
The first issue has an easy solution: assign guests user IDs of our choosing
for the purpose of the database. Actual users have positive integer IDs on
a forum. Therefore, I opted to assign guests negative IDs and identify them
by name. In other words, if guest “Bob” is encountered, they’re assigned
user ID -1. If guest “cindy_123” is encountered next, they’re assigned user
ID -2. If a guest named “Bob” is encountered again, we query the database
User table for existing guests by that name (instead of querying by ID as we
would a registered user), find that guest Bob already exists with ID -1,
and simply use that.
This also hints at how I’ve chosen to handle adding guests to the database: when a post by a guest is encountered, we have to first query the database for existing guests with the same name. If one already exists, use the existing (negative) user ID; if not, assign a new negative ID and use that. This requires the scraper to query the database, which is facilitated by the ScraperManager’s insert_guest() method.
The download_image() and insert_image() functions serve a similar purpose, allowing us to download and add a user’s avatar to the database and reference it while scraping a user profile.
Putting it all together
We now have a complete picture of the scraper, its various components, and how they fit together.
Functions in the scraper call methods in a ScraperManager instance to retrieve the HTML page source for forum URLs, parse the returned HTML, and (with some exceptions) add items to the ScraperManager’s async queues. The ScraperManager, in turn, pops items from those queues and passes them to the appropriate Database instance methods. Finally, the Database instance interacts with the SQLite database to return query results and/or insert the items into the database.
While the details are specific to this particular problem, the guiding principles can be applied to a variety of scraping tasks. In the next two posts, we’ll see how the theory in this post translates to code.