
Code: https://github.com/nrsyed/proboards-scraper
Documentation: https://nrsyed.github.io/proboards-scraper
- Part 1: Introduction and background
- Part 2: Implementation (project structure and scraper initialization)
- Part 3: Implementation (scraper internals)
This post and the next will detail the implementation of the web scraper and dive into the code. These posts are intended to go into significantly more depth than the average web scraping tutorial. We won’t run through all ~1400 lines of code in the repository, but will touch on key components. Moreover, rather than discuss each component of the scraper one by one, we’ll follow the flow of data through the program and through those components as it runs. This means we’ll jump between different files and functions, but in a manner that illustrates how the moving parts work together.
Project structure
The project—a Python package I’ve named proboards_scraper—is
organized as follows:
proboards_scraper/
├── __init__.py
├── __main__.py
├── core.py
├── http_requests.py
├── scraper_manager.py
├── database
│ ├── __init__.py
│ ├── database.py
│ └── schema.py
└── scraper
├── __init__.py
├── scrape.py
└── utils.pyAt the top level, the package has functions for HTTP session management and making HTTP requests, which reside in http_requests.py. The ScraperManager class is defined in scraper_manager.py. core.py is what ties everything together and actually runs the scraper.
The package also contains two submodules. The database submodule encapsulates the Database class (defined in database.py) and the SQLAlchemy table schema (in schema.py), which maps tables in the SQLite database to SQLAlchemy Python objects. The scraper submodule contains async functions (and non-async helpers) for parsing HTML returned by HTTP requests.
Finally, there’s a command-line interface (CLI), which is defined in __main.py__. For more information on the CLI, refer to the documentation.
Creating a SQLAlchemy database session
The scraper is initialized and kicked off by the run_scraper() function in core.py. First, we create an instance of the Database class by pointing it to the database file (named forum.db by default); if the file doesn’t exist, it will automatically be created in the process.
|
|
To see what happens in Database.__init__(), let’s jump to the Database class constructor in database.py:
|
|
Here, we create a SQLAlchemy engine, which we then bind to a SQLAlchemy session. This StackOverflow answer provides a helpful definition of these terms. An “engine” is a low-level object that maintains a pool of connections to actually talk to the database. A “session,” on the other hand, is a higher level object that handles the ORM functionality, i.e., mapping Python objects to SQL database tables/queries. A session uses an engine under the hood to perform database operations.
The Base object on line 95 is a SQLAlchemy metaclass, returned by the
factory function declarative_base(), from which all database table
classes must inherit. In simpler terms, Base.metadata.create_all() links
the engine to the tables we’ve defined.
Those tables are defined in schema.py. Specifically, we’ve defined a Python class for each table. For example, this is the definition for the Board class:
|
|
SQLAlchemy takes care of creating these tables (as well as the database) if
they don’t already exist. Note that the relationship and association_proxy
attributes in the class definition are SQLAlchemy constructs that exist
for our convenience; they aren’t in the actual SQL database schema. In the
Board class, these attributes make it such that when we query the
database for a board, the resulting Board instance will have attributes
named moderators, sub_boards, and threads; these are lists of User
objects, Board objects, and Thread objects, respectively, with foreign keys
that tie them to the Board instance. Normally, each of these would involve a
separate SQL query, but SQLAlchemy handles this for us.
Initializing an authenticated HTTP session
Next, run_scraper() creates a Selenium WebDriver and an aiohttp session:
|
|
Creating an HTTP session without logging in (“authenticating”) isn’t required, but any password-protected or restricted areas of the forum won’t be accessible without it. We’ll use Selenium to log in, since it allows us to interact with webpages and do things like fill out and submit forms. However, Selenium has limitations; a Selenium WebDriver is essentially just a browser window and doesn’t support asynchronous programming, which is vital for the scraper. Furthermore, it doesn’t handle multiple simultaneous connections. In theory, because a Selenium WebDriver “session” is a browser, we could open multiple tabs, but keeping track of those tabs and switching between them adds a considerable amount of complexity and overhead. It also doesn’t address the lack of async support, hence why I opted to use aiohttp scraping and HTTP requests via aiohttp.ClientSession.
However, there’s an obstacle here. When we log in with Selenium, the login cookies are stored in the Selenium WebDriver session. There’s no simple way to transfer these cookies to the aiohttp session, and the two libraries store cookies in different formats. We must convert them manually.
All of the aforementioned functionality lives in http_requests.py. The function get_login_cookies() takes the Selenium WebDriver instance, as well as the login username/password, and returns a list of dictionaries, where each dictionary represents a cookie. The function get_login_session() uses these to construct a dictionary of morsel objects and add them to the aiohttp session’s cookie jar:
|
|
Defining async tasks
The scraper is flexible in that it can be run on any of:
- the entire forum, including all users and all content (if given the URL to the homepage)
- all users (if given the URL to the members page)
- a single user (if given the URL to a specific user profile)
- a single board (if given the URL to a specific board)
- a single thread (if given the URL to a specific thread)
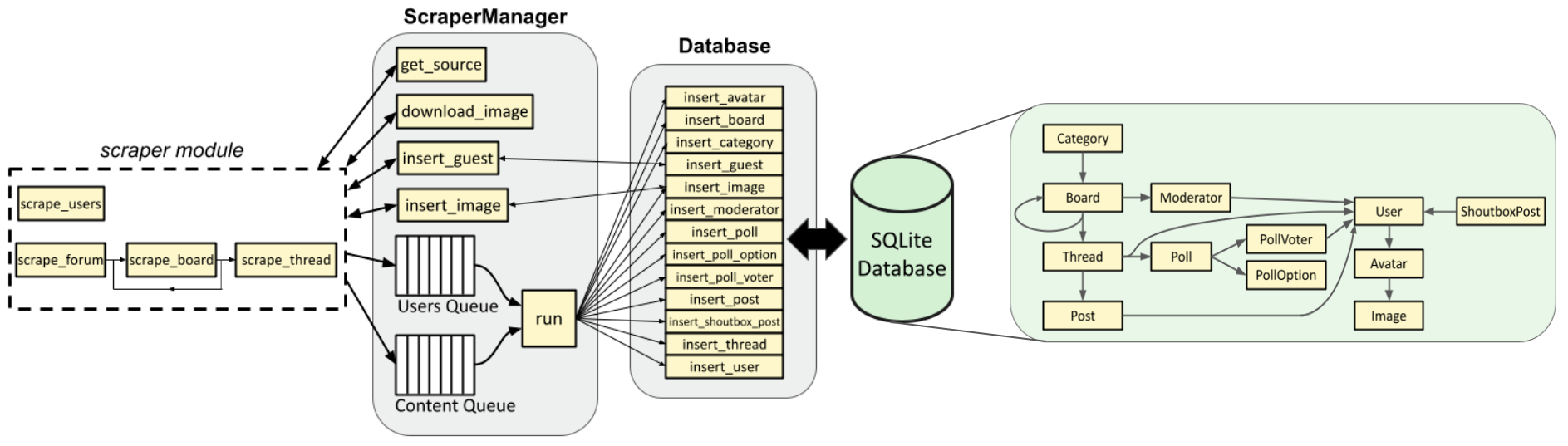
Recall the scraper’s architecture, whereby the scraper module functions add items to either an async “users queue” or an async “content queue”:
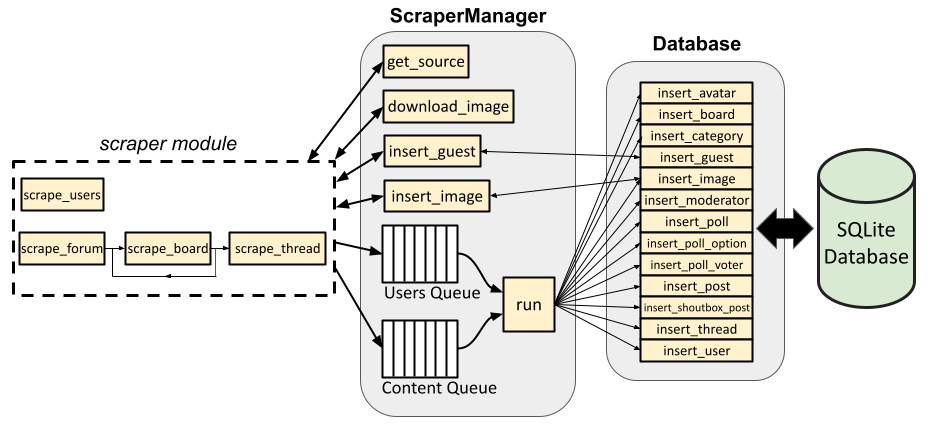
In the list above, option 1 has both a “user” task (responsible for scraping all users and adding them to the users queue) and a “content” task (responsible for scraping all other content and adding it to the content queue). Options 2 and 3 have just a “user” task (responsible for scraping all users or a single user and adding them to the users queue). Options 4 and 5 have just a “content” task. However, each one calls a different function; option 1 calls scrape_users() and scrape_forum(), option 2 calls scrape_users(), option 3 calls scrape_user() (which isn’t shown in the diagram but is an async helper function for scrape_users()), option 4 calls scrape_board(), and option 5 calls scrape_thread().
To simplify the act of creating an async task for a given function with the appropriate queue, we use a private helper function named _task_wrapper():
|
|
To see how this is put into practice, we return to run_scraper.py:
|
|
Note how we add the async task(s) to a list. This allows us to kick off all
tasks in the list and run the asyncio event loop until all tasks have
completed, as in this block of code at the end of run_scraper(), where we
also add ScraperManager.run() and call it database_task, since it pops
items from the queues and calls the appropriate Database instance methods
for inserting those items into the database:
|
|
In this manner, we can kick off a variable number of tasks (depending on whether we’re scraping content, users, or both). Now, the actual scraping can begin. This will be covered in the next post.